Методы оптимизации асинхронных операций в .NET
Статья посвящена методам управления состояниями асинхронных операций на платформе .NET с целью минимизации аллокаций в управляемой памяти. Проведён анализ типичных сценариев использования асинхронного программирования в клиент-серверных приложениях. Основное внимание уделено следующим аспектам: синхронное завершение асинхронных функций, стратегии кеширования задач Task и Task<T>, применение типов ValueTask и ValueTask<T>, реализации интерфейса IValueTaskSource<T>. Приведены результаты тестирования различных типов асинхронных методов на примере вычисления функции Аккермана. Статья предназначена для разработчиков программного обеспечения, работающих над созданием высокопроизводительных и отзывчивых .NET-приложений, в которых критически важна оптимизация ресурсоёмких асинхронных операций.
Введение
Принцип асинхронного программирования состоит в том, что длительно выполняющиеся (или потенциально длительно выполняющиеся) функции реализуются асинхронным образом. Он отличается от традиционного подхода синхронной реализации длительно выполняющихся функций с последующим их вызовом в новом потоке или в задаче для введения параллелизма по мере необходимости.
Асинхронный подход обеспечивает:
- параллельное выполнение операций ввода-вывода без связывания потоков;
- уменьшение количества кода в рабочих потоках обогащенных клиентских приложений (соотносимо с понятием «толстый» клиент).
Это приводит к двум сценариям использования асинхронного программирования.
Первый сценарий касается серверных приложений, которые обрабатывают множество параллельных операций ввода-вывода. В таких приложениях важна не безопасность потоков (разделяемое состояние минимально), а эффективность их использования, чтобы поток, обрабатывающий клиентские запросы, не простаивал на сетевых операциях. Асинхронность особенно полезна для операций с интенсивным вводом-выводом в этом контексте (рис. 1).
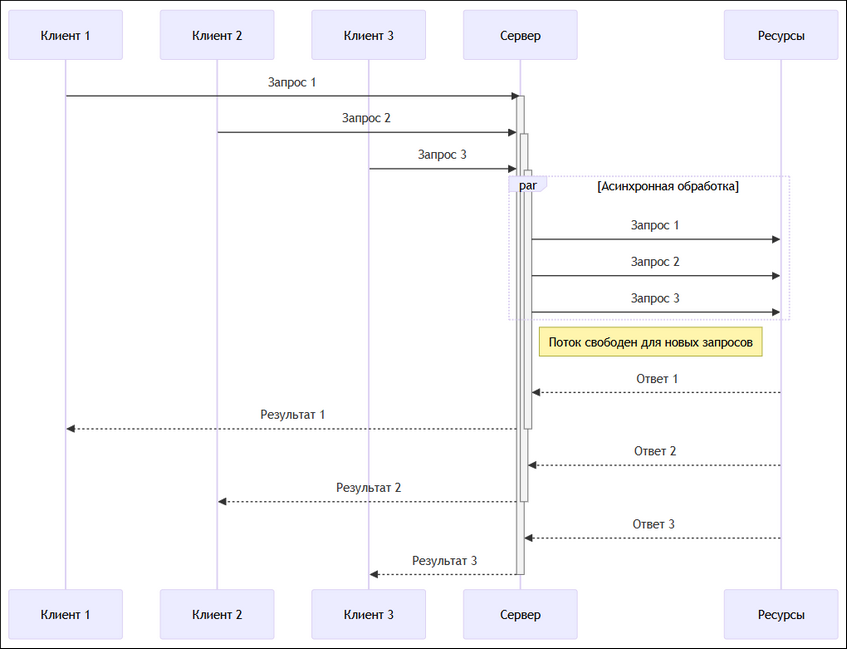
Рисунок 1 – Пример клиент-серверное взаимодействия
Второй сценарий упрощает поддержку потокобезопасности в обогащенных клиентских приложениях, для которых в целях упрощения программы проводится рефакторинг крупных методов в методы меньших размеров, получая в результате цепочки методов, которые вызывают друг друга (графы вызовов). Если любая операция в графе синхронных вызовов длительная, то весь граф запускается в рабочем потоке (или рабочих потоках) для сохранения отзывчивости пользовательского интерфейса (рис. 2). Так реализуется крупномодульный параллелизм.
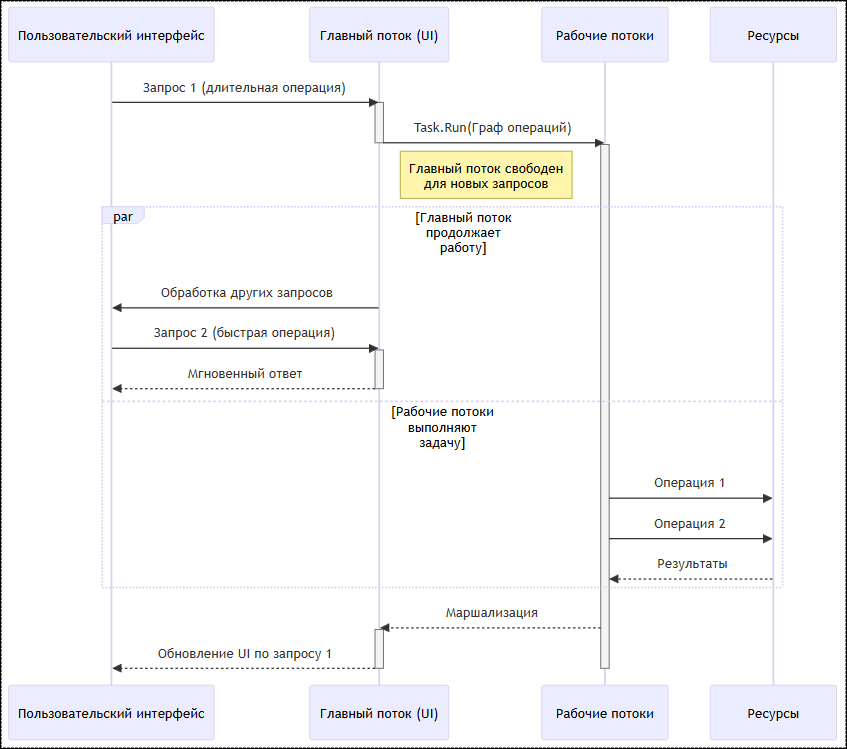
Рисунок 2 – Пример потокового взаимодействия в обогащенном клиентском приложении
Продемонстрируем крупномодульный параллелизм на примере. Пусть имеется метод, вычисляющий количество простых чисел, используя все доступные ядра:
1
2
3
4
5
6
7
8
9
int GetPrimesCount(int start, int count)
{
// Создаем диапазон чисел от start до start + count
return Enumerable.Range(start, count)
.AsParallel().Count(n =>
// Проверяем, является ли число n простым
Enumerable.Range(2, (int)Math.Sqrt(n) - 1).All(i => n % i > 0)
);
}
Метод для отображения количества простых чисел:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
void DisplayPrimeCounts()
{
// Проходим по диапазону чисел, увеличивая каждый раз на 1000000
for (int i = 0; i < 10; i++)
{
// Выводим количество простых чисел в каждом диапазоне
int start = i * 1000000 + 2;
int count = 1000000;
int primeCount = GetPrimesCount(start, count);
Console.WriteLine($"{primeCount} простых чисел между {i * 1000000} и {(i + 1) * 1000000 - 1}");
}
// Уведомляем о завершении
Console.WriteLine("Готово!");
}
Крупномодульный параллелизм для вышеуказанного графа вызовов можно инициировать следующим образом:
1
Task.Run(() => DisplayPrimeCounts());
Результат работы программы представлен на рисунке 3. Выполнение метода DisplayPrimeCounts в параллельном потоке позволяет не блокировать основной поток программы.
Метод Task.Run позволяет вернуть объект Task. Данный объект представляет собой объект-обещание (promise), который позволяет по требованию представить результат фоновой работы или создать функцию обратного вызова (callback), которая будет активизирована после завершения фоновой работы.
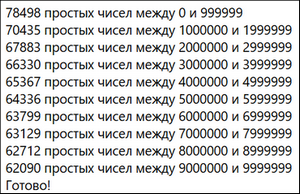
Рисунок 3 – Вывод программы
Если в ходе работы вышеуказанной программы вывод результата следует обеспечить в пользовательском интерфейсе приложения (UI), то следует не забывать об ограничении: элементы UI доступны только из создавшего их потока (главного потока), прямое обновление элементов пользовательского интерфейса из рабочего потока недопустимо. Вместо этого применяется маршализация – перенаправление запросов на обновление UI в главный поток 1, что позволяет сохранить отзывчивость приложения и избежать ошибок при работе с пользовательским интерфейсом.
Маршализация обеспечивается с помощью специальных методов:
- WPF:
Dispatcher.BeginInvokeилиInvoke, - UWP:
Dispatcher.RunAsyncилиInvoke, - Windows Forms:
Control.BeginInvokeилиInvoke.
Эти методы принимают делегат с кодом для выполнения. BeginInvoke/RunAsync ставят делегат в очередь сообщений UI-потока. Invoke делает то же, но блокируется до обработки сообщения, позволяя получить возвращаемое значение. BeginInvoke/RunAsync предпочтительнее, так как не блокируют вызывающий компонент.
Однако, следует быть аккуратным при разработке многопоточного приложения с пользовательским интерфейсом. Например, если инициировать выполнение вышеуказанного кода через обработчик события Click как показано ниже, возникновение условия состязаний неизбежно (переменная i изменяется рабочим потоком и считывается UI-потоком единовременно, делая решение не потокобезопасным).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
_button.Click += (sender, args) =>
{
_button.IsEnabled = false;
Task.Run(() => Go());
};
void Go()
{
for (int i = 0; i < 10; i++)
{
int result = GetPrimesCount(i * 1000000 + 2, 1000000);
Dispatcher.BeginInvoke(new Action(() => _results.Text += result + " простых чисел между " + (i * 1000000) + " и " + ((i + 1) * 1000000 - 1) + Environment.NewLine));
}
Dispatcher.BeginInvoke(new Action(() => button.IsEnabled = true));
}
Мелкомодульный параллелизм – последовательность небольших параллельных операций, между которыми выполнение возвращается в главный поток пользовательского интерфейса. Например, методы, отвечающие за отражение промежуточных результатов, не требуют значительного времени и могут выполняться в основном потоке, что упрощает потокобезопасность. Для реализации асинхронного подхода с мелкомодульным параллелизмом метод GetPrimesCount следует переписать следующим образом.
1
2
3
4
5
6
Task<int> GetPrimesCountAsync(int start, int count)
{
return Task.Run(() =>
Enumerable.Range(start, count).AsParallel().Count(n =>
Enumerable.Range(2, (int)Math.Sqrt(n) - 1).All(i => n % i > 0)));
}
Далее метод DisplayPrimeCounts требует модификации для использования GetPrimesCountAsync.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// Цикл, который выполняется 10 раз
for (int i = 0; i < 10; i++)
{
// Асинхронный вызов метода для подсчета простых чисел
var awaiter = GetPrimesCountAsync(i * 1000000 + 2, 1000000).GetAwaiter();
// Устанавливаем действие, которое будет выполнено по завершении асинхронной операции
awaiter.OnCompleted(() =>
// Выводим результат подсчета простых чисел
Console.WriteLine(awaiter.GetResult() + " простых чисел между... ")
);
}
// Выводим сообщение о завершении всех операций
Console.WriteLine("Готово!");
Неблокирующий вызов в цикле приводит к параллельному выполнению всех 10 операций и преждевременному выводу “Готово!”.
Чтобы обеспечить последовательное выполнение асинхронных операций и корректное завершение программы требуется выполнить два шага:
1) Заменяем цикл for на рекурсивный метод:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
void DisplayPrimeCounts()
{
DisplayPrimeCountsFrom(0);
}
// Рекурсивный метод для отображения количества простых чисел, начиная с определенного индекса
void DisplayPrimeCountsFrom(int i)
{
// Получаем awaiter для асинхронной операции подсчета простых чисел
var awaiter = GetPrimesCountAsync(i * 1000000 + 2, 1000000).GetAwaiter();
// Устанавливаем действие, которое будет выполнено по завершении асинхронной операции
awaiter.OnCompleted(() =>
{
// Выводим результат подсчета простых чисел
Console.WriteLine(awaiter.GetResult() + " простых чисел между...");
// Проверяем, нужно ли продолжать подсчет
if (i++ < 10)
DisplayPrimeCountsFrom(i); // Рекурсивный вызов для следующего диапазона
else
Console.WriteLine("Готово!"); // Выводим сообщение о завершении всех операций
});
}
2) Для асинхронного выполнения самого метода DisplayPrimeCounts с возвратом Task, используем TaskCompletionSource:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
// Асинхронный метод для отображения количества простых чисел
Task DisplayPrimeCountsAsync()
{
var machine = new PrimesStateMachine();
machine.DisplayPrimeCountsFrom(0);
return machine.Task;
}
// Класс, отвечающий за состояния подсчета простых чисел
class PrimesStateMachine
{
// TaskCompletionSource для управления завершением всей операции
TaskCompletionSource<object> _tcs = new TaskCompletionSource<object>();
// Свойство, возвращающее задачу, которая будет завершена по окончании всех операций
public Task Task => _tcs.Task;
// Метод для отображения количества простых чисел, начиная с определенного индекса
public void DisplayPrimeCountsFrom(int i)
{
// Получаем awaiter для асинхронной операции подсчета простых чисел
var awaiter = GetPrimesCountAsync(i * 1000000 + 2, 1000000).GetAwaiter();
// Устанавливаем действие, которое будет выполнено по завершении асинхронной операции
awaiter.OnCompleted(() =>
{
// Выводим результат подсчета простых чисел
Console.WriteLine(awaiter.GetResult());
// Проверяем, нужно ли продолжать подсчет
if (i++ < 10)
DisplayPrimeCountsFrom(i); // Рекурсивный вызов для следующего диапазона
else
{
Console.WriteLine("Готово!"); // Выводим сообщение о завершении всех операций
_tcs.SetResult(null); // Устанавливаем результат TaskCompletionSource, сигнализируя о завершении
}
});
}
}
К счастью, благодаря использованию ключевых слов async и await, представленных в .NET Framework 4.5 и C# 5.0, код становится более лаконичным, так как компилятор формирует код, обеспечивающий всю необходимую работу по управлению асинхронными операциями.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// Асинхронный метод для отображения количества простых чисел в различных диапазонах
async Task DisplayPrimeCountsAsync()
{
// Цикл для подсчета простых чисел в 10 различных диапазонах
for (int i = 0; i < 10; i++)
{
// Асинхронно получаем количество простых чисел в текущем диапазоне
int primeCount = await GetPrimesCountAsync(i * 1000000 + 2, 1000000);
// Выводим результат с указанием диапазона
Console.WriteLine(primeCount +
" простых чисел между " + (i * 1000000) + " и " + ((i + 1) * 1000000 - 1));
}
// Выводим сообщение о завершении подсчета
Console.WriteLine("Готово!");
}
Таким образом, ключевые слова async и await позволяют писать асинхронный код, который обладает той же самой структурой и простотой, что и синхронный код, а также устранять необходимость во вспомогательном коде, присущем асинхронному программированию.
Перечислим основные преимущества асинхронного программирования:
1) Реализация ожидания: ключевое слово await упрощает присоединение признаков продолжения. Приведенные ниже строки:
1
2
3
4
5
6
7
8
9
var результат = await выражение;
оператор(ы);
компилятор развернет в следующий функциональный эквивалент:
var awaiter = выражение.GetAwaiter();
awaiter.OnCompleted(() =>
{
var результат = awaiter.GetResult();
оператор(ы);
});
2) Захват локального состояния: await может располагаться внутри циклов и других конструкций. Пример демонстрирует использование await в цикле for:
1
2
3
4
5
async void DisplayPrimeCounts()
{
for (int i = 0; i < 10; i++)
Console.WriteLine(await GetPrimesCountAsync(1 * 1000000 + 2, 1000000));
}
При встрече await, управление возвращается вызывающему коду. После завершения асинхронной операции, выполнение возобновляется с того места, где оно было прервано. При возобновлении сохраняются значения локальных переменных и счетчиков циклов.
3) Ожидание в пользовательском интерфейсе: в возобновлении выполнения после выражения await компилятор полагается на признаки продолжения (согласно шаблону объектов ожидания). Это значит, что в случае запуска в потоке пользовательского интерфейса контекст синхронизации гарантирует, что выполнение будет возобновлено в том же самом потоке (т.е. в потоке UI). Когда запускается обработчик события (в коде которого присутствует await), например, по нажатию на кнопку, выполнение продолжается до выражения await, после чего управление возвращается в цикл сообщений:
1
2
3
4
5
6
7
while (приложение не завершено)
{
Ожидать появления чего - нибудь в очереди сообщений
Что - то получено: к какому виду сообщений оно относится?
Сообщение клавиатуры/ мыши->запустить обработчик событий
Пользовательское сообщение Beginlnvoke / Invoke->выполнить делегат
}
Это обеспечивает освобождение пользовательского интерфейса для реагирования на дальнейшие события (в то время как рабочая задача, которому предшествовало ключевое слово await, выполняется параллельно потоку UI). Расширение компилятором выражения await гарантирует, что перед возвращением продолжение настроено так, чтобы выполнение возобновлялось там, где оно было прекращено до завершения задачи. И поскольку ожидание с помощью await происходит в потоке пользовательского интерфейса, признак продолжения отправляется контексту синхронизации, который выполняет его через цикл сообщений, сохраняя выполнение всего кода обработчика псевдопараллельным с потоком пользовательского интерфейса.
Целесообразность применения асинхронного программирования несомненна при работе с операциями ввода-вывода и трудоемкими по времени вычислениями. Однако, чрезмерная асинхронность может снизить производительность из-за накладных расходов связанных с выделением объектов-обещаний в управляемой памяти (куче). Для понимания временных затрат, вызываемых работой сборщика мусора, вкратце рассмотрим механизм управления кучей.
Стандартная среда CLR использует сборщик мусора с поддержкой поколений, пометки и сжатия, который осуществляет автоматическое управление памятью для объектов, хранящихся в управляемой куче. При этом каждый процесс имеет как свою собственную кучу, так и свой независимый сборщик мусора, что обеспечивает изоляцию управляемой памяти для каждого приложения в .NET. Сборщик мусора отслеживает граф объектов, хранящихся в управляемой куче, с целью определения объектов, которые могут расцениваться как мусор и потому подвергаться сборке. Процесс сборки инициируется при выделении памяти (через ключевое слово new) либо после того, как выделенный объем памяти превысил определенный порог, либо в другие моменты, чтобы уменьшить объем памяти, занимаемой приложением. Сборщик мусора начинает со ссылок на корневые объекты и проходит по графу объектов, помечая все затрагиваемые им объекты как достижимые (рис. 4). После завершения процесса все объекты, которые не были помечены, считаются неиспользуемыми и пригодными к сборке мусора.
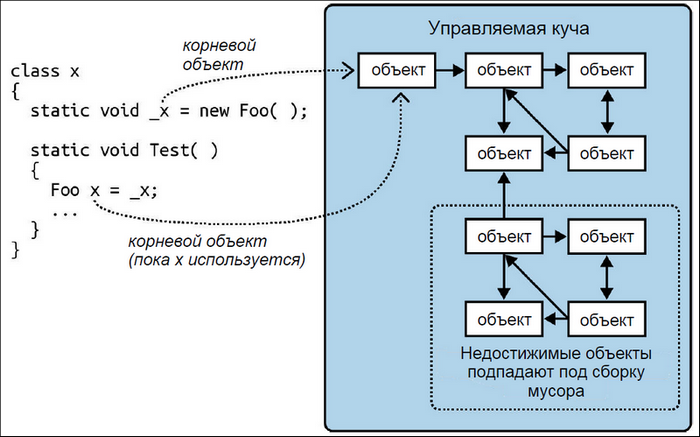
Рисунок 4 – Пример корневых объектов
Обратите внимание, что группа объектов, которые циклически ссылаются друг на друга, считается висячей, если отсутствует ссылка из корневого объекта. Таким образом, объекты, которые не могут быть доступны за счет следования по стрелкам (ссылкам) из корневого объекта, попадают под сборку мусора.
Неиспользуемые объекты без финализаторов отбрасываются немедленно, а неиспользуемые объекты с финализаторами помещаются в очередь для обработки потоком финализаторов после завершения сборщика мусора. Эти объекты затем становятся пригодными к сборке при следующем запуске сборщика мусора для данного поколения объектов (если только они не будут восстановлены). Оставшиеся активные объекты затем смещаются в начало кучи (сжимаются), освобождая пространство под дополнительные объекты. Сжатие служит двум целям: оно устраняет фрагментацию памяти и позволяет сборщику мусора при выделении памяти под новые объекты применять очень простую стратегию – всегда выделять память в конце кучи. Подобный подход позволяет избежать выполнения потенциально длительной задачи по ведению списка сегментов свободной памяти.
По существу, сборщик мусора разделяет управляемую кучу на три поколения. Объекты, которые были только что распределены, относятся к поколению Gen0 (с типичном размером от сотен килобайтов до нескольких мегабайтов), объекты, выдержавшие один цикл сборки – к поколению Gen1, а все остальные объекты – к поколению Gen2. Поколения Gen0 и Gen1 называются недолговечными. Среда CLR сохраняет раздел Gen0 относительно небольшим (с типичным размером от сотен килобайтов до нескольких мегабайтов). Когда раздел Gen0 заполняется, сборщик мусора вызывает сборку Gen0 – что происходит относительно часто. Сборщик мусора применяет похожий порог памяти к разделу Gen1 (который действует в качестве буфера для Gen2), поэтому сборки Gen1 тоже являются относительно быстрыми и частыми. Однако полные сборки мусора, включающие Gen2, занимают намного больше времени и в итоге происходят нечасто. Результат полной сборки мусора показан на рисунке 5.
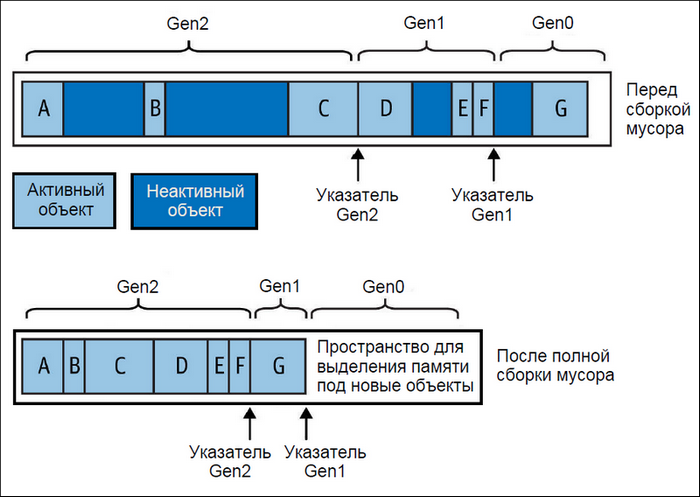
Рисунок 5 – Поколения кучи
Сборка Gen0 может занимать менее одной миллисекунды, так что заметить её в типовом приложении нереально. Но полная сборка мусора в программе с крупными графами объектов может длиться 100 мс. и более. Цифры могут варьироваться – особенно в случае раздела Gen2, размер которого не ограничен (в отличие от разделов Gen0 и Gen1).
Целью исследования является разработка методов асинхронного программирования, обеспечивающих эффективное управление состояниями асинхронных операций при снижении накладных расходов на управление памятью. Основное внимание уделяется следующим аспектам:
- синхронное завершение асинхронной функции,
- кеширование
Task/Task<T>, - применение структуры
ValueTask/ValueTask<T>, - реализация
IValueTaskSource<T>.
Синхронное завершение асинхронной функции
Возврат из асинхронной функции может произойти перед организацией ожидания. Рассмотрим следующий код, который обеспечивает кеширование в процессе загрузки веб-страниц:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
static async Task Main()
{
string html = await GetWebPageAsync("https://csharpcooking.github.io");
html.Length.Dump("Страница загружена");
// Попробуем снова. В этот раз должно быть мгновенно:
html = await GetWebPageAsync("https://csharpcooking.github.io");
html.Dump("Страница загружена");
}
static Dictionary<string, string> _cache = new Dictionary<string, string>();
async Task<string> GetWebPageAsync(string uri)
{
string html;
if (_cache.TryGetValue(uri, out html)) return html;
return _cache[uri] = await new WebClient().DownloadStringTaskAsync(uri);
}
При ожидании задачи компилятор оптимизирует код, проверяя свойство IsCompleted. Если задача уже завершена (например, при наличии данных в кеше), выполнение происходит с возвратом завершённого экземпляра задачи без создания продолжения. Это называется синхронным завершением. В противном случае создается продолжение для асинхронного выполнения. Такой подход позволяет избежать накладных расходов на асинхронность, когда она не требуется, ускоряя выполнение кода, когда данные доступны немедленно.
В представленном примере ожидание асинхронной функции, которая завершается синхронно, все равно связано с небольшими накладными расходами (компилятор все равно добавляет код для управления состоянием метода и возможным продолжением) – примерно 20 наносекунд на современных компьютерах. Напротив, переход в пул потоков вызывает переключение контекста – возможно одну или две микросекунды, а переход в цикл обработки сообщений пользовательского интерфейса – минимум в десять раз больше (и еще больше, если пользовательский интерфейс занят).
Асинхронное программирование в C# предоставляет интересную возможность: создавать асинхронные методы, которые фактически никогда не используют ключевое слово await. Например, можно написать метод вида:
1
async Task<string> Foo() { return "abc"; }
Хотя компилятор и выдаст предупреждение об отсутствии await, такой код вполне допустим и работоспособен. Эта техника особенно полезна при переопределении виртуальных или абстрактных методов в ситуациях, когда ваша конкретная реализация не требует асинхронности. Яркий пример такого подхода можно найти в методах ReadAsync и WriteAsync класса MemoryStream. В данном случае асинхронная обработка не принесет существенного выигрыша в производительности (операции в памяти выполняются очень быстро и не блокируют поток) и может даже ухудшить её из-за накладных расходов на управление задачами и контекстом. Альтернативный способ достижения того же результата заключается в использовании метода Task.FromResult, который возвращает уже завершенную задачу. В этом случае метод может выглядеть так:
1
Task<string> Foo() { return Task.FromResult("abc"); }
Этот вариант не требует использования ключевого слова async. Оба подхода позволяют сохранить согласованность интерфейса и обеспечивают гибкость при реализации асинхронных интерфейсов. Они особенно полезны, когда необходимо работать с асинхронным кодом в преимущественно синхронных сценариях. Важно отметить, что в обоих случаях возвращается сигнализированная (завершенная) задача. Когда же метод помечен как async и использует await, компилятор автоматически генерирует состояние машины (state machine) для управления асинхронными операциями. Это включает в себя создание нескольких объектов и структур для управления жизненным циклом задачи, что влечет за собой дополнительные накладные расходы.
Таким образом, рассмотренные техники предоставляют разработчикам эффективные инструменты для балансирования между асинхронным и синхронным кодом в рамках единой системы, обеспечивая при этом соответствие асинхронным интерфейсам.
Если наш метод GetWebPageAsync вызывается из потока пользовательского интерфейса, то он является неявно безопасным к потокам в том смысле, что его можно было бы вызвать несколько раз подряд (инициируя тем самым множество параллельных загрузок) без необходимости в каком-либо блокировании с целью защиты кеша. Однако если бы последовательность обращений относилась к одному и тому же URI, то инициировалось бы множество избыточных загрузок, которые все в конечном итоге обновляли бы одну и ту же запись в кеше. Хоть это и не ошибка, но более эффективно было бы сделать так, чтобы последующие обращения к тому же самому URI взамен (асинхронно) ожидали результата выполняющегося запроса.
Существует простой способ достичь указанной цели, не прибегая к блокировкам или сигнализирующим конструкциям. Вместо кеша строк мы создаем объект-обещания (Task<string>) – кеш «будущего»:
1
2
3
4
5
6
7
static Dictionary<string, Task<string>> _cache = new Dictionary<string, Task<string>>();
Task<string> GetWebPageAsync(string uri)
{
Task<string> downloadTask;
if (_cache.TryGetValue(uri, out downloadTask)) return downloadTask;
return _cache[uri] = new WebClient().DownloadStringTaskAsync(uri);
}
Обратите внимание, что мы не помечаем метод как async, поскольку напрямую возвращаем объект задачи, полученный в результате вызова метода класса WebClient.
Теперь при повторяющихся вызовах метода GetWebPageAsync с тем же самым URI мы гарантируем получение одного и того же объекта Task<string>. Это обеспечивает и дополнительное преимущество минимизации нагрузки на сборщик мусора. И если задача завершена, то ожидание не требует больших затрат благодаря описанной выше оптимизации, которую предпринимает компилятор.
Чтобы сделать код безопасным к потокам без защиты со стороны контекста синхронизации, необходимо блокировать все тело метода:
1
2
3
4
5
6
lock (_cache)
{
Task<string> downloadTask;
if (_cache.TryGetValue(uri, out downloadTask)) return downloadTask;
return _cache[uri] = new WebClient().DownloadStringTaskAsync(uri);
}
В данном решении мы производим блокировку не на время загрузки страницы (это нанесло бы ущерб параллелизму), а на небольшой промежуток времени, пока проверяется кеш и при необходимости запускается новая задача, которая обновляет кеш.
Кеширование Task/Task<T>
Одной из ключевых концепций в асинхронном программировании является использование класса Task, который представляет собой асинхронную операцию. Однако, несмотря на все свои преимущества, Task имеет потенциальную слабую сторону, особенно когда создается большое количество его экземпляров. Когда асинхронные методы выполняются часто и создают множество объектов Task, это может привести к значительным накладным расходам. Каждый объект Task должен быть создан и размещен в управляемой куче, что требует дополнительных затрат ресурсов на его управление и последующую уборку сборщиком мусора.
Среда выполнения .NET предоставляет механизмы для снижения числа создаваемых объектов в управляемой памяти. Когда метод завершается синхронно, нет необходимости создавать новый объект Task. Вместо этого можно использовать уже существующий экземпляр, что значительно уменьшает накладные расходы.
Для иллюстрации рассмотрим следующий пример:
1
2
3
4
5
6
7
8
public async Task WriteAsync(byte value)
{
if (_bufferedCount == _buffer.Length)
{
await FlushAsync();
}
_buffer[_bufferedCount++] = value;
}
В данном примере, если метод завершается синхронно, ему не нужно возвращать новый Task, так как возвращаемое значение отсутствует. В таких случаях платформа .NET использует кешированный необобщенный Task, который возвращает пустое значение (эквивалент void в синхронных методах). Этот кешированный синглтон доступен через свойство Task.CompletedTask. (Слово «синглтон» (от англ. «singleton») в программировании обозначает паттерн проектирования, который ограничивает создание экземпляра класса одним объектом.)
Таким образом, если в методе WriteAsync буфер заполнен, вызывается метод FlushAsync, который является асинхронным и возвращает Task. Однако, если в буфере достаточно свободного пространства, операция записи выполняется синхронно, и новый объект Task не создается.
Или, например, представим код, в котором метод NextValueAsync имеет возвращаемый объект типа Task<bool>:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
static Random r = new Random();
static int _random;
public static async Task Main(string[] args)
{
List<Task<bool>> taskList = new List<Task<bool>>();
for (int i = 0; i < 1000; i++)
{
taskList.Add(NextValueAsync());
}
// Ожидаем завершения всех задач
await Task.WhenAll(taskList);
// Группируем задачи по результату и проверяем эквивалентность экземпляров
var groupedTasks = taskList.GroupBy(task => task.Result);
foreach (var group in groupedTasks)
{
var firstTask = group.First();
bool allSame = group.All(task => object.ReferenceEquals(task, firstTask));
Console.WriteLine(allSame
? $"Все задачи с результатом {group.Key} являются одним и тем же экземпляром."
: $"Не все задачи с результатом {group.Key} являются одним и тем же экземпляром.");
}
}
static async Task<bool> NextValueAsync()
{
await RandomWithAsyncDelay(false);
return _random > 0;
}
static async Task RandomWithAsyncDelay(bool setAsync)
{
if (setAsync) await Task.Delay(1000);
_random = r.Next(0, 2);
}
Поскольку есть только два возможных результата типа bool (true и false), то существует только два возможных объекта Task, которые нужны для представления этих результатов. В сценарии синхронного завершения среда .NET обеспечивает кеширование этих объектов, возвращая их с соответствующим значением без выделения памяти. Только в случае асинхронного завершения (достигается вызовом RandomWithAsyncDelay с параметром setAsync равным true) методу понадобится создать новый Task, потому что его нужно будет вернуть до того, как станет известен результат операции. Вывод программы при различных значениях параметра setAsync представлен на рисунках 6 и 7.
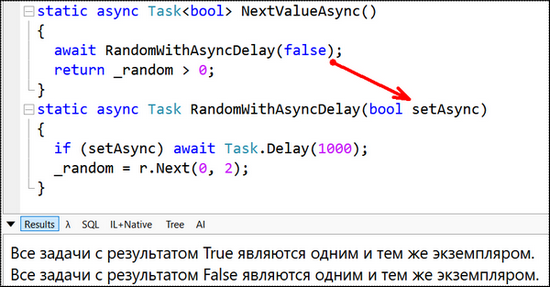
Рисунок 6 – Вывод программы при setAsync = false
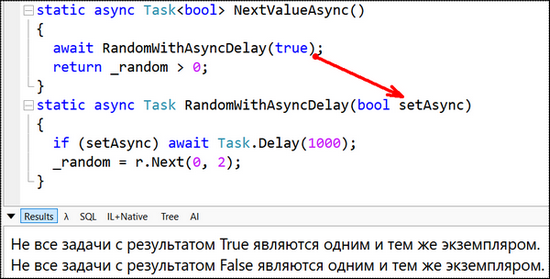
Рисунок 7 – Вывод программы при setAsync = true
При использовании Task<int> в качестве типа возвращаемого объекта асинхронного метода наблюдается иная ситуация. Кеширование всех возможных значений Task<int> потребовало бы сотни гигабайт памяти, так как Int32 представляет собой 32-битное целое число со знаком, которое может принимать около 4,3 миллиарда уникальных значений (в диапазоне от -2147483648 до 2147483647). Поэтому среда выполнения предоставляет ограниченный кеш для Task<int>, покрывающий только небольшой набор значений: значения Task<int> кешируются для диапазона значений от -1 до 9 (для подтверждения и получения дополнительной информации можно обратиться к исходному коду в репозитории dotnet/runtime на GitHub, конкретно к файлу «Task.cs» 2). Это означает, что если метод возвращает значение в этом диапазоне, то будет использована кешированная задача, а не создана новая.
Множество методов библиотеки стремятся сгладить ситуацию за счет использования собственного кеша. В частности, в .NET Framework 4.5 метод MemoryStream.ReadAsync всегда выполняется синхронно, поскольку он считывает данные из памяти (данный метод можно найти в исходном коде .NET на GitHub 3). ReadAsync возвращает Task<int>, где результат типа Int32 указывает количество прочитанных байтов. Этот метод часто применяется в циклах, зачастую с одинаковым количеством требуемых байтов при каждом вызове. Поэтому для повторных вызовов ReadAsync вполне логично ожидать, что Task<int> будет возвращаться синхронно с тем же значением, что и в предыдущем вызове. В связи с этим MemoryStream создает кеш для одного объекта, который вернулся в последнем успешном вызове. При следующем вызове, если результат совпадает, он вернет кешированный объект, в противном случае создаст новый с помощью Task.FromResult, сохранит его в кеш и вернет. Примерный фрагмент кода, который включает реализацию метода ReadAsync, выглядит следующим образом:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public override Task<int> ReadAsync(byte[] buffer, int offset, int count, CancellationToken cancellationToken)
{
if (cancellationToken.IsCancellationRequested)
return Task.FromCanceled<int>(cancellationToken);
try
{
int n = Read(buffer, offset, count);
Task<int>? t = _lastReadTask;
if (t != null && t.Result == n) return t;
_lastReadTask = t = Task.FromResult<int>(n);
return t;
}
catch (Exception exc)
{
return Task.FromException<int>(exc);
}
}
Применение структуры ValueTask/ValueTask<T>
.NET Core 2.0 ввел новый тип ValueTask<TResult>, доступный через NuGet пакет System.Threading.Tasks.Extensions, чтобы решить проблему создания ненужных объектов Task<TResult> при синхронных операциях. (NuGet – это менеджер пакетов для платформы .NET, который позволяет разработчикам добавлять сторонние библиотеки в свои проекты, управлять зависимостями и обновлениями библиотек.) ValueTask<TResult>позволяет оборачивать как TResult, так и Task<TResult>. При синхронном и успешном выполнении асинхронного метода, структура ValueTask<TResult> возвращается без размещения объекта в куче. Только при асинхронном выполнении создается объект Task<TResult>, который затем оборачивается в ValueTask<TResult>. Если асинхронный метод завершается с исключением, для представления этого исключения используется объект Task<TResult>, который затем оборачивается в ValueTask<TResult>. Это позволяет ValueTask<TResult> оставаться компактной структурой, которая не требует отдельного поля для хранения исключения. Пример:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public async ValueTask<int> ExampleMethodAsync()
{
try
{
// Выполнение асинхронной операции
int result = await SomeAsyncOperation();
return result;
}
catch (Exception ex)
{
// Если возникает исключение, оно будет упаковано в Task<int>
return new ValueTask<int>(Task.FromException<int>(ex));
}
}
В этом примере, если SomeAsyncOperation завершается синхронно и успешно, ValueTask<int> просто вернет результат. Если возникает исключение, создается Task<int> с этим исключением, и ValueTask<int> оборачивает его, сохраняя компактность структуры. Применение конструкции await Task.FromException<int>(ex) в завершении метода привело бы к созданию дополнительного кода, необходимого для управления продолжением выполнения программы. В отличие от этого, использование конструкции new ValueTask<int>(Task.FromException<int>(ex)) является более производительным решением. Оно позволяет сразу вернуть экземпляр структуры ValueTask<int>, снижая накладные расходы. Такой подход оптимизирует работу программы за счет исключения ненужных операций, связанных с асинхронным управлением. Возможность написания асинхронного метода, который может завершиться синхронно без дополнительных затрат на выделение памяти для хранения результата, является значительным достижением. Именно по этой причине в .NET Core 2.0 был введен тип ValueTask<TResult>, и теперь методы, которые часто используются в критически важных участках кода, определяются с возвращаемым значением ValueTask<TResult> вместо Task<TResult>. Например, когда в .NET Core 2.1 была добавлена новая перегрузка метода ReadAsync для класса Stream, позволяющая передавать Memory<byte> вместо byte[], тип возвращаемого значения этого метода был изменен на ValueTask<int>. Это позволило значительно сократить объем выделяемой памяти при использовании потоков (Stream), где метод ReadAsync очень часто завершается синхронно, как это наблюдается в случае с MemoryStream. (Для сведения: Memory<byte> в отличие от byte[] позволяет создавать “срезы” (subspans), которые являются ссылками на часть исходного блока памяти без необходимости копирования данных, что снижает накладные расходы и улучшает производительность, особенно при работе с большими объемами данных или при частом создании подмассивов.)
Однако, при разработке высокопроизводительных сервисов по-прежнему важно минимизировать любое выделение памяти, включая размещения в куче объектов, которые связаны с асинхронными операциями. В решениях с await для любой операции, завершающейся асинхронно, необходимо вернуть объект, представляющий будущее завершение операции: вызывающему коду требуется обеспечить передачу делегата (callback), который указывает на метод, выполнение которого следует обеспечить после завершении асинхронной операции. Это требует наличия уникального объекта в куче, который будет служить проводником для выполнения данного делегата. Тем не менее, это не исключает возможности повторного использования такого объекта после завершения операции. Если объект может быть использован повторно, API может поддерживать кеш таких объектов и использовать его для последовательных операций. Это означает, что один и тот же объект не может быть использован для нескольких параллельных асинхронных операций, но может быть многократно использован для неконкурентного доступа.
В .NET Core 2.1 тип ValueTask<TResult> был усовершенствован для поддержки пула объектов и их повторного использования. Вместо того чтобы просто оборачивать TResult или Task<TResult>, был введен новый интерфейс IValueTaskSource<TResult>, и ValueTask<TResult> был дополнен возможностью оборачивать его. IValueTaskSource<TResult> обеспечивает основную функциональность, необходимую для представления асинхронной операции в ValueTask<TResult>.
Основные методы IValueTaskSource<TResult>:
GetStatus(short token): этот метод используется для проверки статуса асинхронной операции. Он возвращает значение типаValueTaskSourceStatus, которое указывает, завершена ли операция, находится ли она в ожидании или завершилась с ошибкой;OnCompleted(Action<object> continuation, object state, short token, ValueTaskSourceOnCompletedFlags flags): этот метод регистрирует обратный вызов (callback), который будет вызван при завершении асинхронной операции;GetResult(short token): этот метод используется для получения результата операции или выброса исключения, если операция завершилась с ошибкой.
Интерфейс IValueTaskSource<TResult> позволяет создавать асинхронные операции, которые могут быть связаны с пулом объектов. Это позволяет многократно использовать один и тот же объект для выполнения разных асинхронных операций, избегая избыточных аллокаций памяти и снижая нагрузку на сборщик мусора. В отличие от IValueTaskSource<TResult> тип Task<TResult> разработан так, чтобы быть безопасным и предсказуемым в многопоточных сценариях. Как только задача завершена, её состояние становится неизменным, и она может быть безопасно использована многократно (например, вызов await может быть выполнен несколько раз). Это означает, что после завершения задачи Task<TResult> она больше не может быть изменена или использована для новой операции.
Проблема повторного использования ValueTask<TResult> хорошо прослеживается на примере следующего кода:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
public class DatabaseReadOperation : IValueTaskSource<string>, IDisposable
{
private static readonly ObjectPool<DatabaseReadOperation> _pool = new DefaultObjectPool<DatabaseReadOperation>(new DefaultPooledObjectPolicy<DatabaseReadOperation>());
private ManualResetEventSlim _completion = new ManualResetEventSlim(false);
private string _result;
private short _token;
public DatabaseReadOperation() { }
public static DatabaseReadOperation Rent(string result)
{
var objPool = _pool.Get();
objPool._result = result;
// objPool._token = (short)Environment.TickCount;
objPool._completion.Reset();
return objPool;
}
public ValueTask<string> StartOperationAsync()
{
return new ValueTask<string>(this, _token);
}
public void Complete()
{
_completion.Set();
}
public string GetResult(short token)
{
if (token != _token)
{
throw new InvalidOperationException("Invalid token");
}
return _result;
}
public ValueTaskSourceStatus GetStatus(short token)
{
if (token != _token)
{
throw new InvalidOperationException("Invalid token");
}
return _completion.IsSet ? ValueTaskSourceStatus.Succeeded : ValueTaskSourceStatus.Pending;
}
public void OnCompleted(Action<object> continuation, object state, short token, ValueTaskSourceOnCompletedFlags flags)
{
if (token != _token)
{
throw new InvalidOperationException("Invalid token");
}
ThreadPool.QueueUserWorkItem(_ =>
{
_completion.Wait();
continuation(state);
});
}
public void Dispose()
{
// Возвращаем объект в пул после завершения
_pool.Return(this);
}
}
public class Program
{
public static async void Main(string[] args)
{
// Первый запрос к базе данных
var objPool = DatabaseReadOperation.Rent("Результат #1");
ValueTask<string> firstValueTask = objPool.StartOperationAsync();
// Обработка запроса
ThreadPool.QueueUserWorkItem(async _ =>
{
string result = await firstValueTask;
Console.WriteLine($"firstValueTask.Result: {result}");
});
// Повторная обработка того же ValueTask (проблема)
ThreadPool.QueueUserWorkItem(async _ =>
{
Thread.Sleep(100); // Симуляция задержки
string result = await firstValueTask;
Console.WriteLine($"firstValueTask.Result: {result}");
});
Thread.Sleep(10); // Симуляция работы сервера
objPool.Complete(); // Завершаем операцию
objPool.Dispose(); // Возвращаем объект в пул
Thread.Sleep(10); // Симуляция задержки до следующего запроса
// Второй запрос к базе данных, используя повторно тот же объект из пула
objPool = DatabaseReadOperation.Rent("Результат #2");
ValueTask<string> secondValueTask = objPool.StartOperationAsync();
// Обработка второго запроса
ThreadPool.QueueUserWorkItem(async _ =>
{
Thread.Sleep(100); // Симуляция задержки
string result = await secondValueTask;
Console.WriteLine($"secondValueTask.Result: {result}");
});
objPool.Complete(); // Завершаем операцию
objPool.Dispose(); // Возвращаем объект в пул
}
}
Вывод программы:
firstValueTask.Result: Результат #1
firstValueTask.Result: Результат #2
secondValueTask.Result: Результат #2
Структурно представим выполнение вышеуказанного кода:
- Первый запрос к базе данных:
1.1. Создается объект objPool типа DatabaseReadOperation, который арендуется из пула (Microsoft.Extensions.ObjectPool.ObjectPool<T>) и используется для первой асинхронной операции. Ему присваивается результат “Результат #1”.
1.2. Запускаются два потока, которые ожидают завершения этой операции. Первый поток немедленно выполняетawait firstValueTask, получает результат и завершает выполнение.
1.3. Второй поток ожидает завершения firstValueTask через 100 миллисекунд. Это ожидание выполняется уже после того, как первый поток завершил выполнение и объектobjPoolвозвращен в пул для повторного использования (см. пункт 2.1 далее). - Второй запрос к базе данных:
2.1. Тот же объектobjPoolповторно арендуется для выполнения второго запроса, и ему присваивается новый результат “Результат #2”.
2.2. Запускается еще один поток, который асинхронно ожидает завершения второй операции.
Таким образом, второй поток, который ожидает завершения firstValueTask через 100 мс. после первого, фактически работает с объектом, который уже был переиспользован для другой операции. Это приводит к ситуации, когда второй поток, ожидающий результат первого запроса, на самом деле получает результат второго запроса, что является ошибочным поведением.
В представленном коде закомментированная строка:
1
objPool.token = (short)Environment.TickCount;
играет важную роль в предотвращении проблемы повторного использования экземпляра ValueTask<TResult>. Эта строка отвечает за обновление токена, который используется для проверки корректности выполнения асинхронной операции. Токен (_token) используется для обеспечения уникальности операции. Каждый раз, когда объект арендуется из пула для новой операции, этот токен должен обновляться. В противном случае, если токен останется прежним, все связанные с этим объектом ValueTask будут указывать на принадлежность текущей операции, даже если объект уже был возвращен в пул и повторно использован для другой операции. Если каждый раз при аренде объекта из пула вы обновляете токен (например, с использованием Environment.TickCount или другого уникального значения), вы гарантируете, что старые ValueTask, связанные с этим объектом, больше не будут действительны. Это предотвращает ситуацию, когда второй поток получает результат, предназначенный для новой операции, что мы видели в предыдущем примере.
Таким образом, возможность повторного использования экземпляра ValueTask<TResult> без негативных последствий определяется правильной реализацией интерфейса IValueTaskSource<TResult>. Важнейшую роль в этом процессе играет корректное управление токенами, которые обеспечивают уникальность и правильную идентификацию каждой асинхронной операции. При правильном использовании IValueTaskSource<TResult> и соответствующей реализации методов интерфейса можно добиться значительного улучшения производительности, минимизируя накладные расходы на память и избегая ошибок, связанных с многократным ожиданием на одном и том же экземпляре ValueTask<TResult>.
Когда ValueTask<TResult> был представлен в .NET Core 2.0, основной акцент был сделан на оптимизации сценариев с синхронным завершением операций, чтобы избежать лишнего выделения памяти под объект Task<TResult>, если результат уже был доступен. Это объясняло отсутствие необходимости в необобщенном классе ValueTask, поскольку для синхронного выполнения можно было просто использовать синглтон Task.CompletedTask, что не требовало создания новых объектов. Однако с развитием технологий и появлением требования исключить выделение памяти даже при асинхронных завершениях операций, необходимость в необобщенном ValueTask вновь стала актуальной. Так в .NET Core 2.1 был представлен необобщенный ValueTask. Это дало возможность управлять асинхронными операциями с минимальными накладными расходами, аналогично обобщенным версиям, но с пустым возвращаемым значением. Освобождение от выделения в куче при асинхронном завершении с использованием необобщенного ValueTask достигается за счет использования необобщенного интерфейса IValueTaskSource, который позволяет реализовать логику асинхронной операции так, чтобы управлять её завершением без необходимости создания нового объекта Task в куче.
В .NET Core 2.1 также были добавлены несколько новых методов API, которые существенно улучшают работу с сокетами. Одними из наиболее значимых являются обновленные перегрузки методов Socket.ReceiveAsync и Socket.SendAsync. Эти методы теперь поддерживают асинхронное выполнение и предоставляют разработчикам более гибкие и эффективные способы работы с сетевыми операциями.
Одной из нововведений является перегрузка:
1
public ValueTask<int> ReceiveAsync(Memory<byte> buffer, SocketFlags socketFlags, CancellationToken cancellationToken = default);
Данная перегрузка возвращает экземпляр ValueTask<int>, который является оптимизированным для случаев, когда операция может завершиться синхронно или асинхронно. В случае синхронного завершения операция возвращает ValueTask<int> с уже известным результатом:
1
2
int result = ...;
return new ValueTask<int>(result);
При асинхронном выполнении метод возвращает ValueTask<int>, основанный на объекте из пула, который реализует интерфейс IValueTaskSource<int>:
1
2
IValueTaskSource<int> vts = ...;
return new ValueTask<int>(vts);
Реализация класса Socket оптимизирована таким образом, что для каждой операции (отправка или получение данных) используется отдельный объект из пула. Это обусловлено тем, что в любой момент времени для каждого направления (прием или передача данных) может ожидать выполнения только одна операция. Важным преимуществом данной реализации является отсутствие выделения дополнительной памяти, даже если операция выполняется асинхронно.
Реализация IValueTaskSource<T> c применением ManualResetValueTaskSourceCore<T>
Реализация интерфейса IValueTaskSource<T> может показаться нетривиальной задачей. Ранее при описании проблемы повторного использования экземпляра ValueTask<TResult> был представлен класс DatabaseReadOperation, реализующий интерфейс IValueTaskSource<string>. В данном коде поток, выполняющий await firstValueTask, узнает о необходимости выполнить продолжение благодаря механизму синхронизации с использованием блокирующей конструкции ManualResetEventSlim, что является минусом.
С введением ManualResetValueTaskSourceCore<TResult> в .NET Core 3.0 ситуация поменялась: данная изменяемая структура предоставляет встроенные механизмы для управления состоянием асинхронной задачи и обработки продолжений, причем обеспечивая данное управление без блокирующих примитивов синхронизации. Экземпляр данной структуры можно использовать в качестве поля на объекте, чтобы помочь ему реализовать интерфейс IValueTaskSource<T>. Представим класс DatabaseReadOperation с применением этой структуры.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
public class DatabaseReadOperation : IValueTaskSource<string>, IDisposable
{
private static readonly ObjectPool<DatabaseReadOperation> _pool = new DefaultObjectPool<DatabaseReadOperation>(new DefaultPooledObjectPolicy<DatabaseReadOperation>());
private ManualResetValueTaskSourceCore<string> _core; // Используем ManualResetValueTaskSourceCore для управления состоянием и результатом
private string _result;
public DatabaseReadOperation() { }
public static DatabaseReadOperation Rent(string result)
{
var objPool = _pool.Get();
objPool._result = result;
objPool._core.Reset(); // Сбрасываем состояние перед повторным использованием
return objPool;
}
public ValueTask<string> StartOperationAsync()
{
return new ValueTask<string>(this, _core.Version);
}
public void Complete()
{
_core.SetResult(_result); // Завершаем операцию и устанавливаем результат
}
public string GetResult(short token)
{
return _core.GetResult(token); // Получаем результат операции
}
public ValueTaskSourceStatus GetStatus(short token)
{
return _core.GetStatus(token); // Получаем статус операции
}
public void OnCompleted(Action<object> continuation, object state, short token, ValueTaskSourceOnCompletedFlags flags)
{
_core.OnCompleted(continuation, state, token, flags); // Регистрируем продолжение
}
public void Dispose()
{
// Возвращаем объект в пул после завершения
_pool.Return(this);
}
}
На рисунке 8 представлен вывод после запуска кода:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
// Первый запрос к базе данных
var objPool = DatabaseReadOperation.Rent("Результат #1");
ValueTask<string> firstValueTask = objPool.StartOperationAsync();
// Обработка запроса
ThreadPool.QueueUserWorkItem(async _ =>
{
string result = await firstValueTask;
Console.WriteLine($"firstValueTask.Result: {result}");
});
// Повторная обработка того же ValueTask (проблема)
ThreadPool.QueueUserWorkItem(async _ =>
{
Thread.Sleep(100); // Симуляция задержки
string result = await firstValueTask;
Console.WriteLine($"firstValueTask.Result: {result}");
});
Thread.Sleep(10); // Симуляция работы сервера
objPool.Complete(); // Завершаем операцию
objPool.Dispose(); // Возвращаем объект в пул
Thread.Sleep(10); // Симуляция задержки до следующего запроса
// Второй запрос к базе данных, используя повторно тот же объект из пула
objPool = DatabaseReadOperation.Rent("Результат #2");
ValueTask<string> secondValueTask = objPool.StartOperationAsync();
// Обработка второго запроса
ThreadPool.QueueUserWorkItem(async _ =>
{
Thread.Sleep(100); // Симуляция задержки
string result = await secondValueTask;
Console.WriteLine($"secondValueTask.Result: {result}");
});
objPool.Complete(); // Завершаем операцию
objPool.Dispose(); // Возвращаем объект в пул
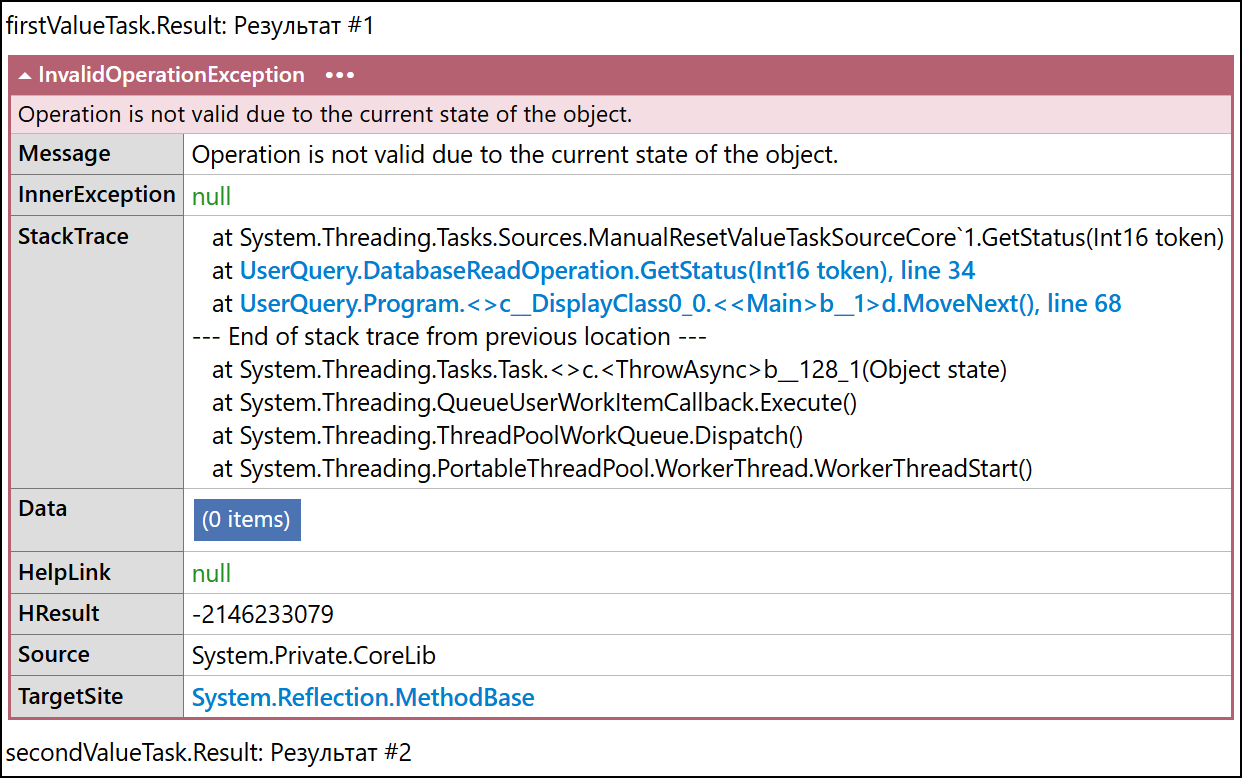
Рисунок 8 – Вывод программы с использованием ManualResetValueTaskSourceCore
На рисунке 8 наблюдается ошибка, потому что токен, переданный в метод GetStatus, больше не соответствует внутреннему состоянию объекта после его повторного использования из пула. Это объясняется следующим.
Сброс (Reset) очищает все внутренние состояния объекта, такие как захваченные контексты выполнения, продолжения, исключения и результат предыдущей операции. После вызова _core.Reset поле _version будет инкрементировано и свойство _core.Version вернет значение, которое не будет соответствовать первоначальному. Это важно для предотвращения ошибок при многократном ожидании завершения одной и той же задачи. В приведенном выше коде объект из пула был возвращен и повторно использован слишком рано, в то время, когда один из потоков все еще ожидал первоначальный объект.
Ограничения на использование ValueTask/ValueTask<T>
Основная причина введения ValueTask заключается в том, чтобы избежать создания объектов задачи (Task), когда результат уже готов или операция завершена синхронно. Однако, такие задачи могут оборачивать повторно используемые объекты, что приводит к ограничениям на их использование по сравнению с Task/Task<TResult>. Рассмотрим ограничения, нарушение которых может привести к некорректной работе программы, состояниям гонки и другим труднодиагностируемым ошибкам.
Первое – многократное ожидание (await) на одном и том же ValueTask/ValueTask<TResult>: поскольку внутренний объект может быть обработан и использоваться в другой операции, многократное ожидание может привести к тому, что объект уже будет занят другой задачей. Это может привести к некорректной работе программы. В отличие от Task, который всегда остается в завершенном состоянии и поддерживает многократные ожидания, ValueTask может перейти в незавершенное состояние при повторном использовании. В программе выше, где рассматривалось использование ManualResetValueTaskSourceCore<string> при реализации интерфейса IValueTaskSource<string>, представлен частный случай нарушения данного ограничения – параллельное ожидание одного и того же ValueTask<string>. Если один и тот же ValueTask ожидается в нескольких потоках одновременно, это создает условия для возникновения гонки.
Второе – использование метода GetAwaiter().GetResult() до завершения операции: в отличие от Task, который поддерживает блокирующий вызов до завершения задачи, реализация IValueTaskSource или IValueTaskSource<TResult> не обязана поддерживать блокировку до завершения операции. Поэтому вызов метода GetResult может привести к состояниям гонки и непредсказуемому поведению программы.
Указанные ограничения определяют важное правило: с экземплярами ValueTask или ValueTask<TResult> вы должны либо ожидать их напрямую с помощью await (возможно с ConfigureAwait(false), указывающее, что после await выполнение кода не обязано возвращаться в исходный контекст синхронизации), либо сразу преобразовать их в Task с помощью метода AsTask, а затем больше не использовать исходный объект.
Рекомендации по использования ValueTask/ValueTask<TResult>:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
// Предположим, у нас есть метод, возвращающий ValueTask<int>
public ValueTask<int> SomeValueTaskReturningMethodAsync();
// ------
// ПРАВИЛЬНО
int result = await SomeValueTaskReturningMethodAsync();
// ------
// ПРАВИЛЬНО
int result = await SomeValueTaskReturningMethodAsync().ConfigureAwait(false);
// ------
// ПРАВИЛЬНО
Task<int> t = SomeValueTaskReturningMethodAsync().AsTask();
// ------
// ПРЕДУПРЕЖДЕНИЕ
ValueTask<int> vt = SomeValueTaskReturningMethodAsync();
// сохранение экземпляра в локальную переменную увеличивает вероятность
// его неправильного использования, но это все еще может быть допустимо
// ------
// НЕПРАВИЛЬНО: ожидание одного и того же ValueTask несколько раз
ValueTask<int> vt = SomeValueTaskReturningMethodAsync();
int result = await vt;
int result2 = await vt; // Это может привести к ошибкам
// ------
// НЕПРАВИЛЬНО: одновременное ожидание (и, как следствие, многократное ожидание)
ValueTask<int> vt = SomeValueTaskReturningMethodAsync();
Task.Run(async () => await vt);
Task.Run(async () => await vt); // Это вызовет состояния гонки и непредсказуемое поведение
// ------
// НЕПРАВИЛЬНО: использование GetAwaiter().GetResult() до завершения задачи
ValueTask<int> vt = SomeValueTaskReturningMethodAsync();
int result = vt.GetAwaiter().GetResult(); // Это может привести к состоянию гонки и ошибкам
Соблюдение этих рекомендаций поможет избежать ошибок и некорректного поведения программы при работе с ValueTask и ValueTask<TResult>.
Из-за представленных ограничений, требующих соблюдения определенных рекомендаций, программисты реже прибегают к использованию ValueTask<TResult>. Поэтому в этом отношении, если производительность не перевешивает удобство использования, Task<TResult> остаются предпочтительными. Кроме того, есть небольшие затраты, связанные с возвращением ValueTask<TResult> вместо Task<TResult>. Например, по результатам тестирования реализаций функции Аккермана 4 ожидание Task<TResult> при определенных значениях параметров функции выполняется быстрее, чем ожидание ValueTask<TResult> (см. таблицу, рисунки 9 и 10 далее). Ниже представлен фрагмент кода программы 5, с помощью которого было проведено данное тестирование.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
static void Main()
{
BenchmarkRunner.Run<Ackermann>();
}
[IterationCount(100)]
[MemoryDiagnoser]
public class Ackermann
{
[Params(1,2,3)]
public int m;
[Params(1,2,3)]
public int n;
[Benchmark(Baseline = true)]
public int Baseline()
{
return AckermannFunc(m, n);
int AckermannFunc(int m, int n) => (m, n) switch
{
(0, _) => n + 1,
(_, 0) => AckermannFunc(m - 1, 1),
_ => AckermannFunc(m - 1, AckermannFunc(m, n - 1)),
};
}
[Benchmark]
public ValueTask<int> ValueTask()
{
return AckermannFunc(m, n);
async ValueTask<int> AckermannFunc(int m, int n) => (m, n) switch
{
(0, _) => n + 1,
(_, 0) => await AckermannFunc(m - 1, 1),
_ => await AckermannFunc(m - 1, await AckermannFunc(m, n - 1)),
};
}
[Benchmark]
public Task<int> Task()
{
return AckermannFunc(m, n);
async Task<int> AckermannFunc(int m, int n) => (m, n) switch
{
(0, _) => n + 1,
(_, 0) => await AckermannFunc(m - 1, 1),
_ => await AckermannFunc(m - 1, await AckermannFunc(m, n - 1)),
};
}
}
Функция Аккермана обладает высокой степенью рекурсивной вложенности. В представленном коде в конечной точке рекурсии происходит синхронное завершение, в результате весь стек вызовов тоже разворачивается синхронно, и выполнение не уходит в асинхронность. В этом случае ValueTask<int> не создаёт Task<int>, и код остаётся полностью стековым, без выделений памяти в куче.
Результаты тестирования реализаций функции Аккермана с применением .NET SDK 9.0.100 и библиотеки BenchmarkDotNet v0.14.0 6 представлены в таблице. Для тестирования была использована целевая платформа с характеристиками:
- процессор Intel Core i5-9300H (8 логических, 4 физических ядра)
- оперативная память DDR4 16 ГБ,
- операционная система Windows 11 (10.0.22631.4460),
- Runtime=.NET 9.0.3 (9.0.325.11113), X64 RyuJIT AVX2.
Таблица – Результаты тестирования реализаций функции Аккермана
| Метод | Число рек. вызовов | m | n | Средн. арифм., нс. | Станд. откл., нс. | Кол-во сборок мусора в Gen0 на 1000 операций | Кол-во выделяемой памяти в куче за 1 вызов метода, байт |
|---|---|---|---|---|---|---|---|
| Baseline | 4 | 1 | 1 | 3,506 | 0,0902 | - | - |
| ValueTask | 4 | 1 | 1 | 76,036 | 2,2531 | - | - |
| IValueTaskSource | 4 | 1 | 1 | 378,316 | 11,3795 | 0,0877 | 368 |
| Task | 4 | 1 | 1 | 50,700 | 1,0317 | - | - |
| Baseline | 6 | 1 | 2 | 7,313 | 0,0782 | - | - |
| ValueTask | 6 | 1 | 2 | 106,601 | 6,3150 | - | - |
| IValueTaskSource | 6 | 1 | 2 | 503,147 | 28,4584 | 0,1354 | 568 |
| Task | 6 | 1 | 2 | 65,809 | 2,1491 | - | - |
| Baseline | 8 | 1 | 3 | 8,576 | 0,2664 | - | - |
| ValueTask | 8 | 1 | 3 | 136,545 | 3,2220 | - | - |
| IValueTaskSource | 8 | 1 | 3 | 678,346 | 19,3167 | 0,1831 | 768 |
| Task | 8 | 1 | 3 | 89,820 | 2,4432 | - | - |
| Baseline | 14 | 2 | 1 | 18,519 | 0,6279 | - | - |
| ValueTask | 14 | 2 | 1 | 270,178 | 7,9779 | - | - |
| IValueTaskSource | 14 | 2 | 1 | 1221,201 | 29,1151 | 0,3242 | 1360 |
| Task | 14 | 2 | 1 | 163,981 | 5,7236 | - | - |
| Baseline | 27 | 2 | 2 | 36,497 | 0,6551 | - | - |
| ValueTask | 27 | 2 | 2 | 482,350 | 11,3347 | - | - |
| IValueTaskSource | 27 | 2 | 2 | 3009,284 | 60,8933 | 0,6599 | 3376 |
| Task | 27 | 2 | 2 | 352,306 | 7,8184 | - | - |
| Baseline | 44 | 2 | 3 | 57,001 | 0,7175 | - | - |
| ValueTask | 44 | 2 | 3 | 814,358 | 28,9962 | - | - |
| IValueTaskSource | 44 | 2 | 3 | 4343,942 | 172,8679 | 1,5030 | 6296 |
| Task | 44 | 2 | 3 | 569,717 | 13,4053 | 0,0515 | 216 |
| Baseline | 106 | 3 | 1 | 135,360 | 1,1921 | - | - |
| ValueTask | 106 | 3 | 1 | 1961,375 | 62,9385 | - | - |
| IValueTaskSource | 106 | 3 | 1 | 10705,974 | 446,4759 | 4,0436 | 16937 |
| Task | 106 | 3 | 1 | 1534,464 | 40,6479 | 0,3777 | 1584 |
| Baseline | 541 | 3 | 2 | 674,350 | 5,9826 | - | - |
| ValueTask | 541 | 3 | 2 | 9459,547 | 181,8086 | - | - |
| IValueTaskSource | 541 | 3 | 2 | 66247,500 | 5013,7841 | 21,8506 | 91701 |
| Task | 541 | 3 | 2 | 9222,128 | 378,4115 | 4,7455 | 19872 |
| Baseline | 2432 | 3 | 3 | 3293,043 | 44,9792 | - | - |
| ValueTask | 2432 | 3 | 3 | 44116,709 | 1783,5449 | - | - |
| IValueTaskSource | 2432 | 3 | 3 | 414282,242 | 17464,7995 | 96,6797 | 416848 |
| Task | 2432 | 3 | 3 | 46579,047 | 1897,1332 | 30,3345 | 126864 |
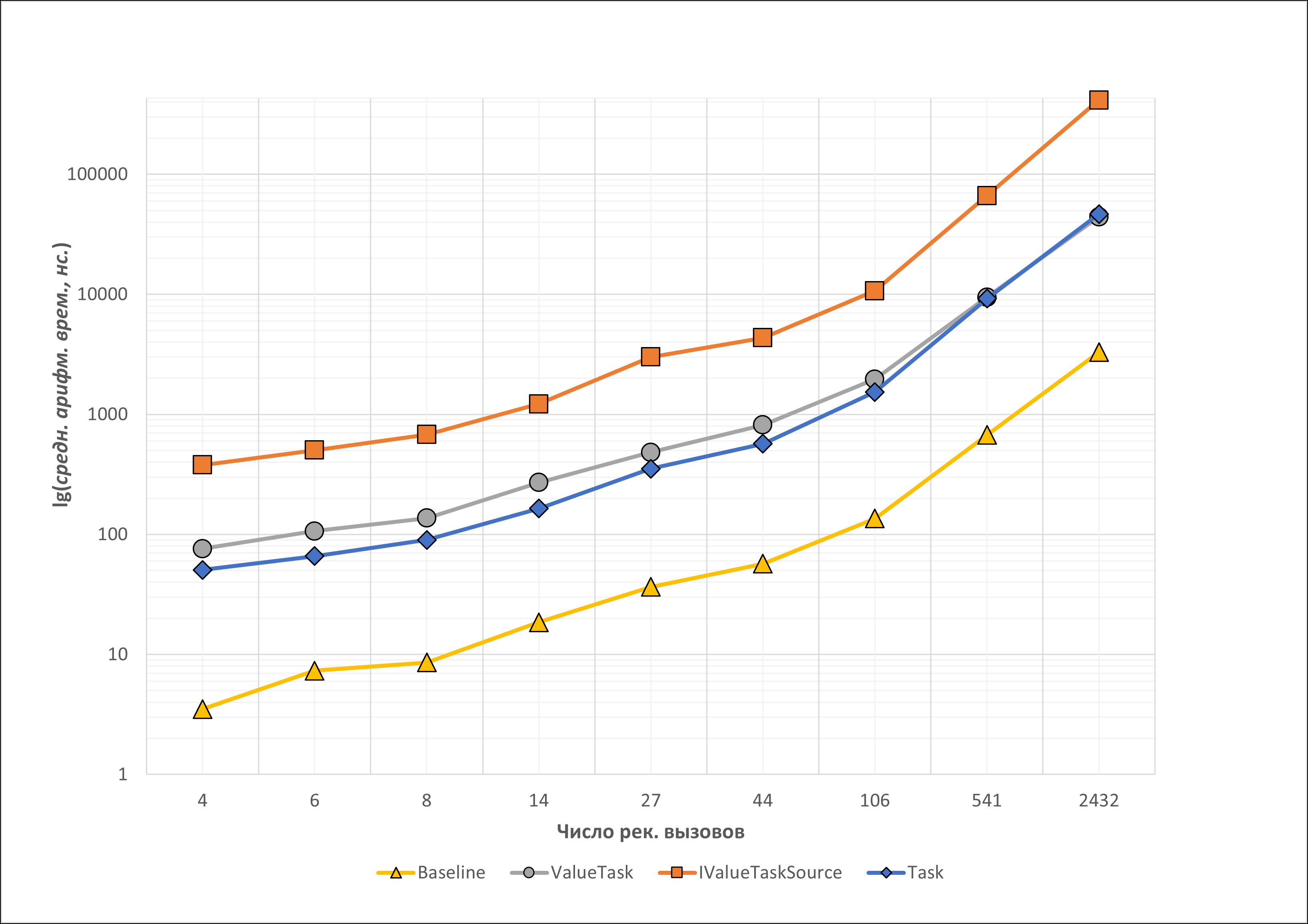
Рисунок 9 – Времена работы методов Baseline, ValueTask, IValueTaskSource, Task
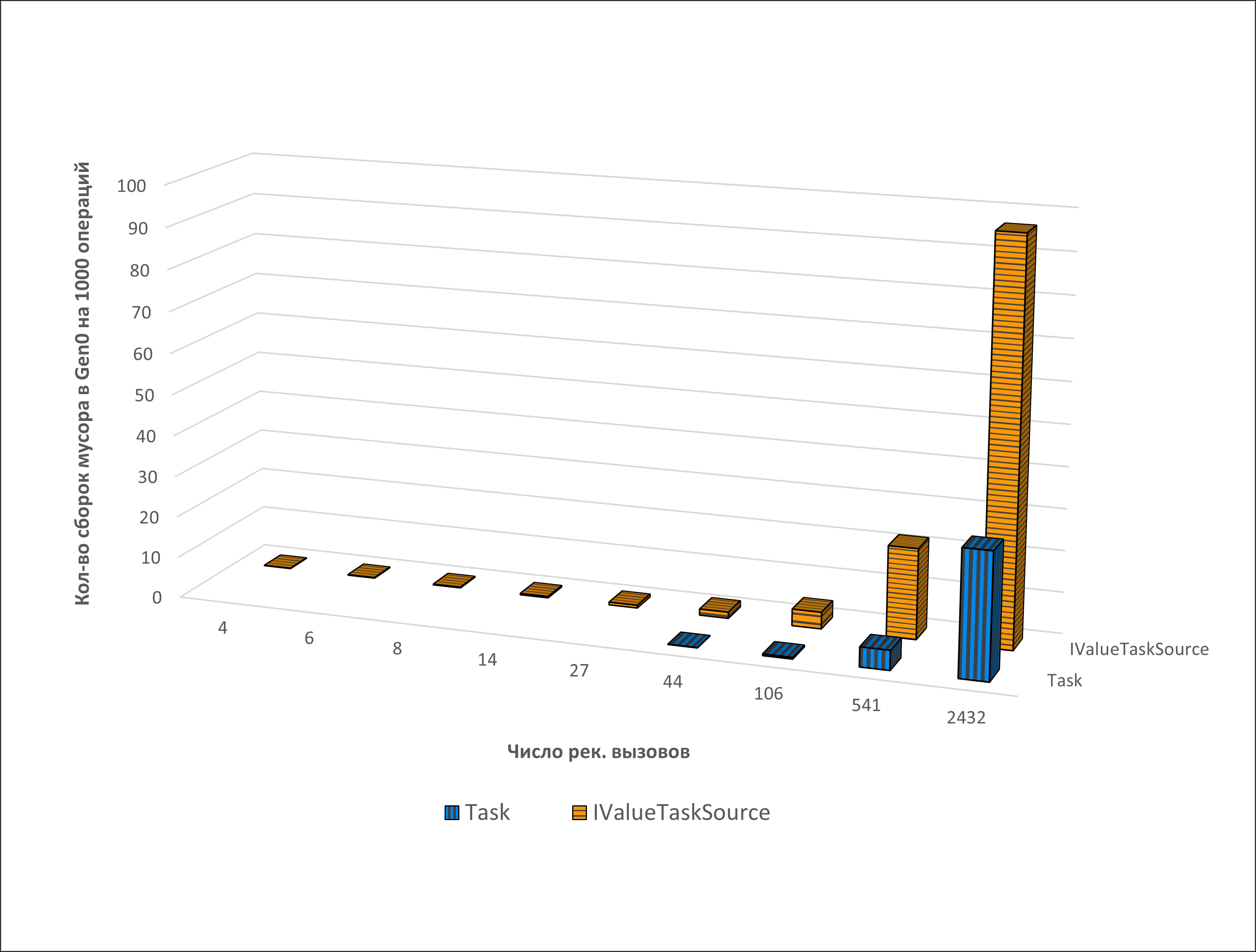
Рисунок 10 – Количество сборок мусора в ходе работы методов Task и IValueTaskSource
Тестирование показало, что при использовании ValueTask<int> не происходит выделения памяти в куче, тогда как Task<int> аллоцирует память при каждом await. Однако скорость работы с Task<int> при малых аллокациях выше, чем при использовании ValueTask<int>. Это обусловлено затратами, связанные с использованием ValueTask<TResult>:
- При передаче экземпляра структуры
ValueTask<TResult>между методами происходит копирование структуры, что влечет дополнительные накладные расходы. В случаеTask<TResult>, передается только указатель на объект в куче. ValueTask<TResult>может представлять: синхронный результат; ссылку наTask<TResult>; объект, реализующий интерфейсIValueTaskSource<TResult>. Это делает управление состоянием более сложным, поскольку метод, использующийValueTask<TResult>, должен учитывать все три случая.
Адаптация функции Аккермана к интерфейсу IValueTaskSource<T> не дало выигрыша ни в производительности, ни в использовании управляемой памяти, так как использование глубокой рекурсии приводит к переполнению пула объектов.
Заключение
Асинхронное программирование в .NET представляет собой мощный инструмент для повышения производительности и отзывчивости приложений, особенно в сценариях, связанных с операциями ввода-вывода или длительными вычислениями. По итогам проведенного анализа сформированы методы оптимизации асинхронных операций:
- Выполнение предварительной проверки завершения асинхронной операции и, если результат уже доступен (например, из кеша), обеспечить синхронное завершение метода, чтобы избежать затрат на создание асинхронной инфраструктуры. Использование кешированных задач, таких как
Task.CompletedTaskилиTask.FromResult, обеспечивает возвращение результата с минимальными накладными расходами. - Применение методов, возвращающих
Task<bool>,Task<int>, позволяет использовать кешированные экземпляры для значений, что исключает необходимость создания новых объектов. - Использование структуры
ValueTask<T>позволяет избежать выделения памяти в куче, оборачивая либо результат, либо объект задачи. Для использования данной структуры требуется соблюдение определенных ограничений, таких как избегание многократного ожидания одного и того же экземпляра. - Реализация механизма управления асинхронными операциями через интерфейс
IValueTaskSource<T>позволяет организовать пул повторно используемых объектов. Такой механизм требует ручного управления состояниями асинхронных операций, чтобы избежать ошибок.
Результаты тестирования в синхронном сценарии на примере функции Аккермана показали, что при малых аллокациях в памяти целесообразно применение Task<T>, так как данный тип не уступает в производительности ValueTask<T>. В асинхронном сценарии с возвращаемой структурой ValueTask<TResult> положительный результат потенциально достижим с применением интерфейса IValueTaskSource<T> и эффективным использованием пула объектов (т.е. не вызывая его переполнения).
Использованные источники
Гибадуллин Р. Ф. Потокобезопасные вызовы элементов управления в обогащенных клиентских приложениях / Р. Ф. Гибадуллин // Программные системы и вычислительные методы. – 2022. – № 4. – С. 1-19. – DOI 10.7256/2454-0714.2022.4.39029. ↩︎
Исходный код класса Task в .NET Runtime [Электронный ресурс] // GitHub: репозиторий dotnet/runtime. – URL: https://github.com/dotnet/runtime/blob/main/src/libraries/System.Private.CoreLib/src/System/Threading/Tasks/Task.cs (дата обращения: 24.08.2025). ↩︎
Исходный код класса MemoryStream в .NET Runtime [Электронный ресурс] // GitHub: репозиторий dotnet/runtime. – URL: https://github.com/dotnet/runtime/blob/main/src/libraries/System.Private.CoreLib/src/System/IO/MemoryStream.cs (дата обращения: 24.08.2025). ↩︎
Козлов Д. А., Говохин Н. А. Исследование функции Аккермана //Технические и математические науки. Студенческий научный форум. – 2018. – С. 96-110. ↩︎
Исходный код программы AsyncAckermannBenchmark [Электронный ресурс] // GitHub: репозиторий CSharpCooking/AsyncAckermannBenchmark. – URL: https://github.com/CSharpCooking/AsyncAckermannBenchmark/blob/main/AsyncAckermannBenchmark/Program.cs (дата обращения: 24.08.2025). ↩︎
Akinshin A. Pro. NET Benchmarking. Apress, 2019. ↩︎